¿Por qué los tokenizers ya no deberían ser una caja negra?
Cuando usamos un modelo de lenguaje, solemos pensar que “lee texto”. Pero no es verdad. Un modelo no ve palabras. Ve números.
Antes de entender una frase, necesita romperla en piezas pequeñas llamadas tokens y convertirlas en identificadores numéricos. Ese proceso, que parece técnico y lejano, en realidad decide mucho más de lo que parece: cuánto texto cabe en contexto, cómo se separan las palabras y hasta qué tan bien entiende un idioma o un dominio concreto.
Por eso el cambio que llega con Transformers v5 es interesante. No porque haga “más rápida” la tokenización, sino porque por fin la vuelve más clara.
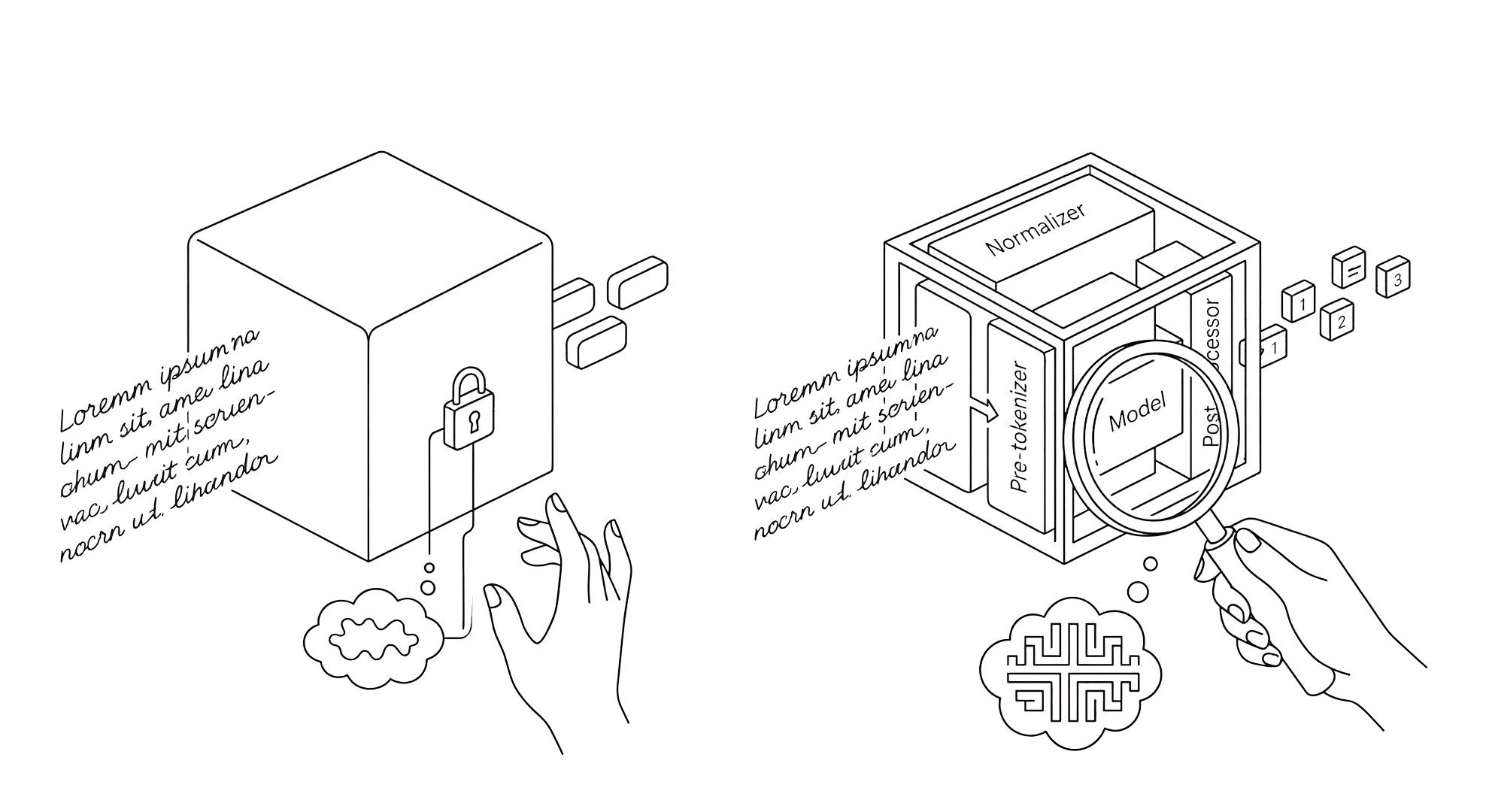
Hasta ahora, muchos tokenizers funcionaban como una caja negra. Cargabas uno desde un modelo y listo. Funcionaba, sí, pero era difícil saber qué estaba pasando dentro. ¿Usaba BPE o Unigram? ¿Cómo trataba los espacios? ¿Qué normalización aplicaba? ¿Dónde colocaba los tokens especiales? Para averiguarlo, había que bucear en archivos internos o documentación dispersa.
Transformers v5 cambia esa idea de raíz. La arquitectura del tokenizer se separa de lo que ha aprendido. Es decir: una cosa es el diseño del sistema y otra su vocabulario entrenado. Se parece mucho a cómo en PyTorch separas la arquitectura de una red neuronal de sus pesos.
Eso tiene una consecuencia muy potente: ahora un tokenizer se puede inspeccionar, entender y entrenar desde cero con mucha menos fricción.
Dicho de forma simple, ya no trabajas solo con un “tokenizer ya hecho”. Puedes empezar con una plantilla clara, ver cómo está construida y luego entrenarla con tus propios datos. Por ejemplo, podrías crear un tokenizer con el mismo comportamiento que el de LLaMA, pero adaptado a textos médicos, jurídicos o a un idioma menos representado.
También hay una mejora práctica importante: menos duplicación y menos confusión. En versiones anteriores había implementaciones “slow” y “fast”, con archivos distintos y comportamientos que a veces no coincidían del todo. En v5, la ruta recomendada es una sola, con backend rápido como opción principal y una jerarquía más limpia.
La idea clave es esta: los tokenizers dejan de ser un detalle oculto del modelo y pasan a ser una pieza visible del sistema.
Y eso importa más de lo que parece. Porque cuando entiendes cómo un modelo corta el lenguaje, entiendes también cómo empieza a pensar sobre él.
Apoya este blog
Si quieres apoyar el blog con una aportación.
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.