La inteligencia artificial generativa suele presentarse como una carrera entre modelos cada vez más potentes. Pero en la práctica, el factor que determina el éxito no es el modelo, sino cómo se integra dentro de un sistema completo. Entender ese sistema —sus capas y decisiones— es lo que separa una demo llamativa de una solución útil.
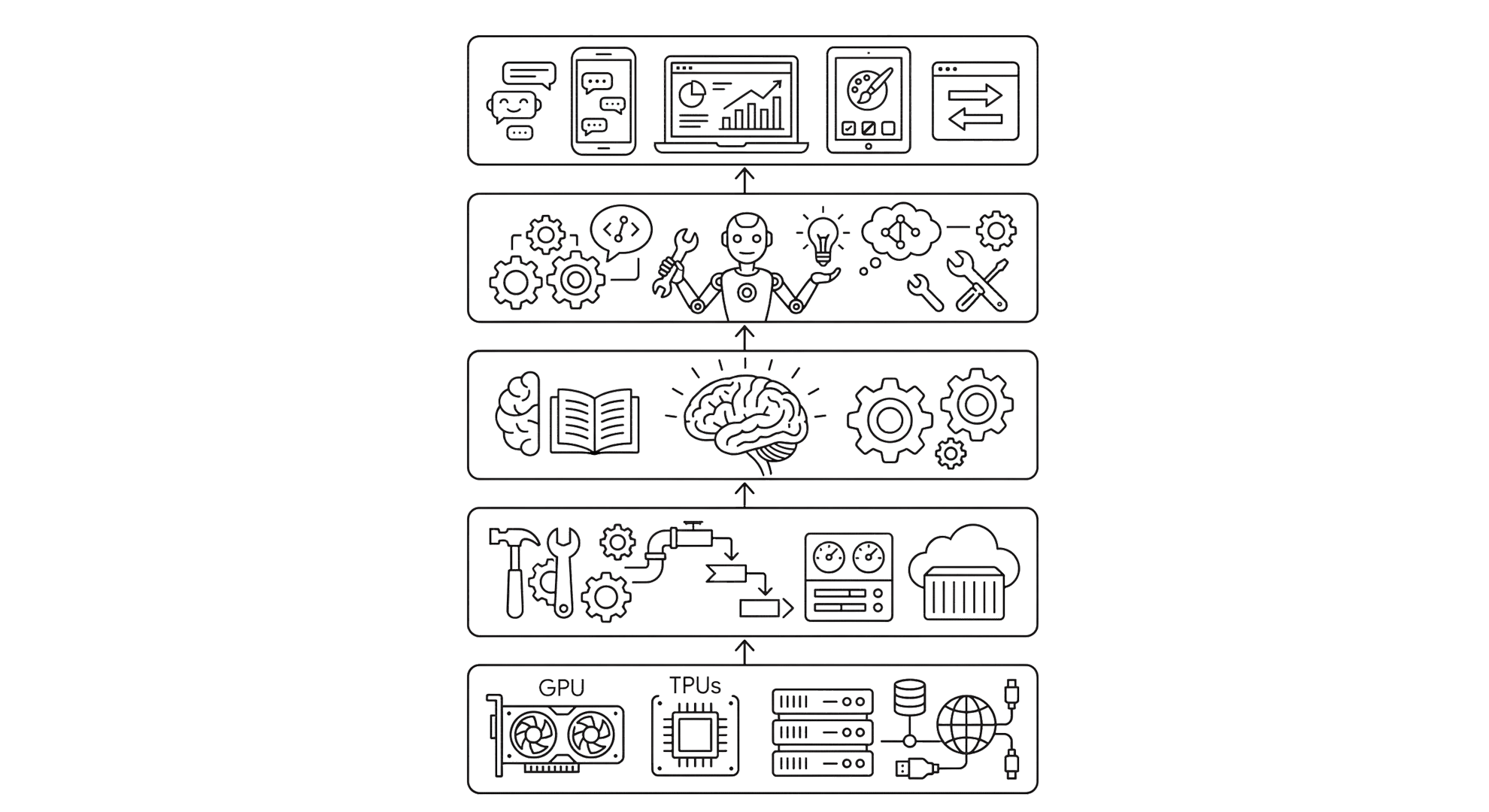
Cuando se habla de “ecosistema”, se refiere a una arquitectura en la que cada capa cumple una función concreta. En la base está la infraestructura, donde viven las GPUs y el almacenamiento que hacen posible el cálculo. Encima aparece la plataforma, como Vertex AI, que actúa como intermediario: no crea inteligencia por sí misma, pero organiza, automatiza y simplifica todo el ciclo de vida del modelo. Sobre esa capa están los modelos, que son el núcleo generativo, y por encima emergen los agentes, capaces de encadenar decisiones y usar herramientas. Finalmente, la aplicación es lo único visible para el usuario. El punto clave es que cada decisión en una capa condiciona a las demás; elegir mal abajo suele amplificar errores arriba.
Aquí es donde plataformas como Vertex AI cobran sentido. Construir sistemas de machine learning desde cero implica orquestar datos, entrenamiento, despliegue y monitorización, un proceso complejo incluso para equipos experimentados. Vertex AI reduce esa complejidad integrando piezas como repositorios de modelos preentrenados, herramientas de entrenamiento automatizado y prácticas de MLOps para escalar. No es solo una herramienta, es una forma de evitar reinventar la infraestructura cada vez.
En este contexto, uno de los errores más frecuentes es empezar por el modelo. Existe una tendencia a pensar que el valor está en crear uno propio, cuando en la mayoría de casos ya hay modelos suficientemente buenos. La decisión real no es “qué modelo construir”, sino “hasta qué punto necesitas adaptarlo”. Usar un modelo existente suele ser suficiente; el fine-tuning introduce especialización cuando el caso lo exige; crear un modelo desde cero queda reservado a escenarios muy específicos donde no hay alternativas viables. Esta jerarquía no es solo técnica, es económica.
La diferencia entre modelos y agentes marca otro punto de inflexión. Un modelo responde a una entrada; un agente, en cambio, estructura un proceso. Esto implica razonar en pasos, decidir cuándo usar herramientas externas y ejecutar acciones. En términos prácticos, el salto de chatbot a agente es el paso de generar texto a resolver tareas. Es ahí donde la IA empieza a tener impacto operativo real.
La ubicación de esa inteligencia también importa. Ejecutar modelos en la nube ofrece escalabilidad y potencia, pero introduce latencia y dependencia de conexión. Llevarlos al “edge”, es decir, al propio dispositivo, cambia las reglas: permite respuestas inmediatas, mayor privacidad y funcionamiento offline. Modelos como Gemini Nano representan este cambio, donde parte de la inteligencia deja de estar centralizada y pasa a integrarse directamente en móviles o sistemas embebidos. No es una sustitución del cloud, sino una redistribución más eficiente según el caso de uso.
Tomar decisiones inteligentes en este entorno no consiste en elegir la tecnología más avanzada, sino en ajustar la solución al problema. Variables como la escala de usuarios, la necesidad de personalización, la latencia tolerable o la sensibilidad de los datos determinan la arquitectura adecuada. Un sistema en tiempo real con datos privados no se diseña igual que un chatbot de atención al cliente. La clave es entender qué sacrificios estás dispuesto a hacer: coste frente a precisión, velocidad frente a complejidad.
Porque el coste, precisamente, es donde muchos proyectos fallan. No se limita al uso del modelo; incluye entrenamiento, despliegue y, sobre todo, operación continua. Cada consulta, cada almacenamiento y cada integración suma. Y a esto se añade el mantenimiento, el componente más subestimado. Un modelo en producción necesita monitorización, actualización de datos y revisiones periódicas. Sin ello, su rendimiento se degrada con el tiempo, aunque el modelo en sí no cambie.
En paralelo, los roles dentro de un proyecto reflejan estas capas. El negocio define el problema y el valor esperado, los desarrolladores construyen la interfaz y la lógica de aplicación, y los especialistas en IA ajustan y optimizan los modelos. No son funciones intercambiables: cada una opera en un nivel distinto del sistema.
La idea que atraviesa todo el ecosistema es sencilla pero fácil de ignorar: la IA generativa no es una pieza aislada, sino un sistema de decisiones interconectadas. Elegir el modelo más potente rara vez compensa una mala arquitectura. En cambio, una solución bien diseñada, aunque use tecnología más simple, suele ser más robusta, más barata y más útil.
La conclusión es directa: en IA generativa, la ventaja no está en la sofisticación, sino en la adecuación. La mejor solución no es la más avanzada, sino la que encaja con precisión en el problema que quieres resolver.
Glosario
LLM (Large Language Model): modelo de lenguaje entrenado con grandes volúmenes de texto capaz de generar y entender lenguaje natural.
MLOps: conjunto de prácticas para automatizar, desplegar y mantener modelos de machine learning en producción.
Fine-tuning: proceso de ajustar un modelo preentrenado con datos específicos para mejorar su rendimiento en una tarea concreta.
Edge computing: ejecución de modelos o procesos en el propio dispositivo del usuario en lugar de en la nube.
Latencia: tiempo que tarda un sistema en responder desde que recibe una solicitud.
Apoya este blog
Si quieres apoyar el blog con una aportación.
Deja una respuesta
Lo siento, debes estar conectado para publicar un comentario.